Let’s talk about why almost every organisation is faced with the problem of big data scaling. Bigger speeds of modern world create large flows of data. For business it is matter of survival to keep computing costs at their minimum. Once the organization starts operating big data, the problem of distributing data sets arises.
Since date volume increases constantly, the storage and computing capacity must grow accordingly. It is vital for such a company to be equipped with database scalability. Not scalable database could and will cause slow down or even fail business operations. Scalability ensures that all customers will be served at less possible time helping to gain profit.
Solution for big data scaling
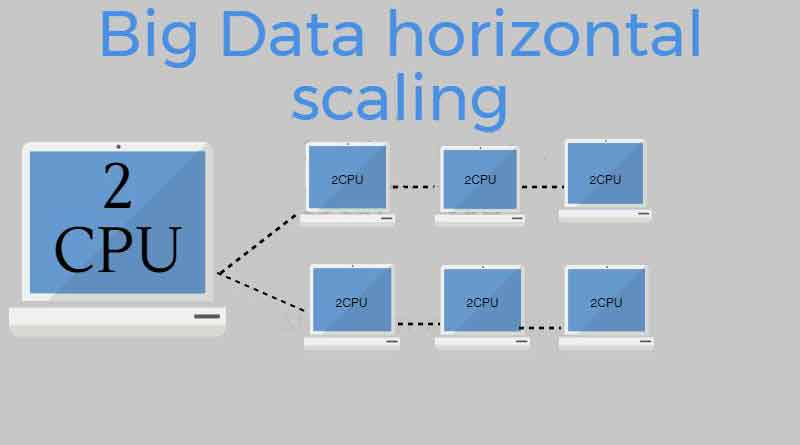
So, in order to increase the storage capacity and the processing power, the best solution to handle data flow is to store the data in a distributed architecture. The procedure of storing and processing data in a distributed architecture is known as Horizontal Scaling. This means, that instead of adding more power to the single machine, i.e. faster CPU, more RAM, SSD etc (“Vertical Scaling”), you just add more computers to a cluster that functions as a single logical unit. It is cost effective and can scale infinitely. When the servers are clustered, the original server is scaled out horizontally. If a cluster requires more resources to improve performance, the administrator can add more servers to the cluster, that means scale-out.
Advantages of horizontal scaling
- Easy to upgrade
- More cost effective compared to vertical scaling
- Better for smaller systems
- Easier troubleshooting
Disadvantages of horizontal scaling
- Higher utility costs
- The licensing fees are more expensive
- Required more networking equipment such as routers and switches
Technologies for big data scaling
There are several technologies to tackle big data flexibility.
- Hadoop (one of the preferred file system for storing Big Data).
- EC2 ELB and ALB load balancers
- AWS
- Kinesis AWS
- Dynamo DB
- Couchbase as cross platform scalable DB
So, to make sure your business pays just right price for the required resources, we have created range of solutions, which are capable to react on spike loads and adjust resources accordingly. Good example here is Dynamo DB. For example, you’ve got an application which monitors reading operations via CloudWatch service. If a spike load hits Dynamo, it’ll be no less than 30 seconds until that information is available through CloudWatch. What we have created is the Dynamo speedometer which monitors your Dynamo read/write speed in real time and if a spike hits your database, it increases capacity immediately. So, absolutely no Data will be lost.
If your organization needs implementing either this technology or any business solution, please contact us and request a quote.