Nowadays more and more companies start to implement Real Time Big Data Analytics in their organisation. In fact, it is not a popular trend, but a necessary part of the business. Here are some examples of how big companies succeeded with Real Time Big Data Analytics.
How Real Time Big Data Analytics help companies
- TESCO is the largest UK’s food retailer. They started tracking customer activities through its loyalty cards. And they managed successfully to transition to online retailing. Last year they decided to apply cutting edge analytics and the most up-to-date big data tracking tools to gain better understanding of: consumer behavior, creating efficiency in their logistics and distribution chains, to keep down costs and minimize impact, reducing amount of food which are wasted, and to create business model to compete with their own. And they were able to manage all these goals described with Real Time Big Data analytics.
- Another success story is Viacom, the largest media company in the world, owner of household brands such as Comedy Central, Nickelodeon and MTV. They broadcast in around 160 countries. Viacom is heavily involved in Big Data. Monitoring of the digital networks which are used to deliver their content into Millions of homes gives them access to a huge amount of data, on how their systems and their audiences behave. They have developed a number of use cases for the network data collection. Thanks to Real Time Big Data analytics tools they improved video experience in the way of distributing resources. Viacom has built a real-time analytics platform which constantly monitors the quality of video feeds and relocates resources in real-time when it thinks it will be needed, for example it allocate minimum or no resources in the areas where everyone is asleep or out of work.
Those stories proves that Real Time Big Data Analytics really helped these companies to stay successful on the market and gave them further development. In fact, there are different ways to analyse traffic. Let’s talk now about how to implement data flow and ability to extract information out of it in your organization.
How to implement Real Time Big Data Analytics in your organisation
We are using AWS (have a look at How to start using AWS to improve your business performance) in almost all my projects. In fact, AWS has a bunch of tools included in Kinesis service which amazingly fit this particular needs. There are ways of using the service via CLI or on web console. But we want to discuss situation when you wish to embed Kinesis service into your application in order to have some programming control over the process.
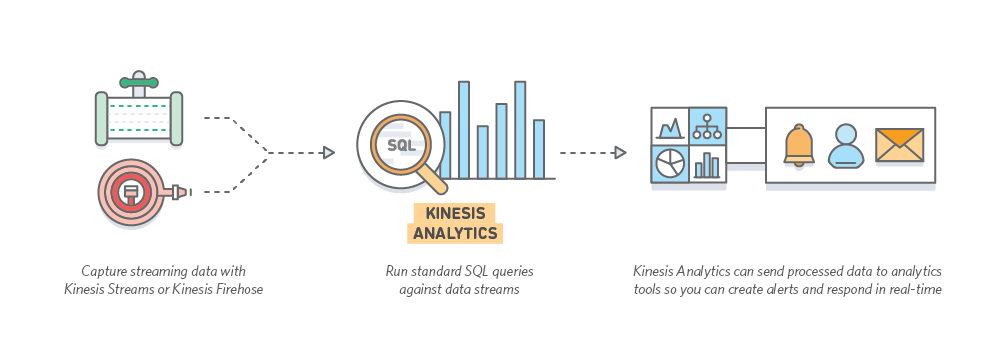
Kinesis itself consists of following parts:
- Streams. This is input source of the data.
- Application. The part is designed for analyzing+ data in the stream.
- Firehose. This service is designed to put data to particular destination.
Sometimes organisation may wish to jump over Application part. Then all data which is getting collected by stream is getting passed to firehose and saved on s3 or Redshift. However, it’s very common when you want to understand what data is telling us in between these steps. So the Application part is designed for this purpose.
What we are interesting in is how easy/hard is to embed this into our current application. So before stream has to be launched and analysed, particular Infrastructure has to be created.
Infrastructure for implementing Real Time Big Data Analytics
- create stream
[code language=”groovy”]
CreateStreamRequest request = new CreateStreamRequest()
request.withStreamName(streamName)
request.withShardCount(minShardCount)
kinesisClient = amazonWebService.getKinesis()
kinesisClient.createStream(request)
waitForStreamToBecomeAvailable(streamName)//Wait until stream is becoming available. This could take a wile and if you send
// request to work with it it could fail with StreamNotFound exception
private void waitForStreamToBecomeAvailable(String streamName) throws InterruptedException {
long startTime = System.currentTimeMillis()
long endTime = startTime + TimeUnit.MINUTES.toMillis(10)
while (System.currentTimeMillis() < endTime) {
Thread.sleep(TimeUnit.SECONDS.toMillis(20))
try {
DescribeStreamRequest request = new DescribeStreamRequest()
request.setStreamName(streamName)
// ask for no more than 10 shards at a time — this is an optional parameter
request.setLimit(maxShardCount)
DescribeStreamResult describeStreamResponse = kinesisClient.describeStream(request)
String streamStatus = describeStreamResponse.getStreamDescription().getStreamStatus()
if ("ACTIVE" == streamStatus) {
return
}
} catch (StreamNotFoundException ex) {
// ResourceNotFound means the stream doesn’t exist yet,
// so ignore this error and just keep polling.
} catch (AmazonServiceException ase) {
//something very very wrong
throw ase
}
}
throw new RuntimeException(String.format("Stream %s never became active", streamName))
}[/code] - create Firehose
[code language=”groovy”]
CreateDeliveryStreamRequest request = new CreateDeliveryStreamRequest()
request.withDeliveryStreamName(firehoseName)
//S3 is gonna be destination in our case
ExtendedS3DestinationConfiguration conf = new ExtendedS3DestinationConfiguration()
conf.setBucketARN(getBucketARN(firehoseS3Bucket))
BufferingHints bufferingHints = null
if (s3DestinationSizeInMBs != null || s3DestinationIntervalInSeconds != null) {
bufferingHints = new BufferingHints()
bufferingHints.setSizeInMBs(s3DestinationSizeInMBs)
bufferingHints.setIntervalInSeconds(s3DestinationIntervalInSeconds)
}
conf.setBufferingHints(bufferingHints)
String iamRoleArn = iamHelperService.createFirehoseIamRole(firehoseS3Bucket)
conf.setRoleARN(iamRoleArn)
conf.setCompressionFormat(CompressionFormat.UNCOMPRESSED)
request.setExtendedS3DestinationConfiguration(conf)
firehoseClient.createDeliveryStream(request)
waitForDeliveryStreamToBecomeAvailable(firehoseName) [/code] - create Application which is gonna process our data. This bit is very tricky so we have to stop on some points more Detailed
[code language=”groovy”]
CreateApplicationRequest request = new CreateApplicationRequest()
request.withApplicationName(name)
String applicationCode = "HERE is your application query code which will be executed"
request.withApplicationCode(applicationCode)
Input input = new Input()
KinesisStreamsInput streamsInput = new KinesisStreamsInput()
//Our Stream we created before
StreamDescription streamDescription = describeStream(STREAM_NAME)
streamsInput.setResourceARN(streamDescription.getStreamARN())
String streamRoleARN = iamHelperService.createAnalyticsStreamIamRole()
streamsInput.setRoleARN(streamRoleARN)
input.setKinesisStreamsInput(streamsInput)
input.setNamePrefix(STREAM_PREFIX)
DiscoverInputSchemaRequest inputSchemaRequest = new DiscoverInputSchemaRequest()
inputSchemaRequest.setResourceARN(streamDescription.getStreamARN())
inputSchemaRequest.setRoleARN(streamRoleARN)
InputStartingPositionConfiguration configuration = new InputStartingPositionConfiguration()
configuration.setInputStartingPosition(InputStartingPosition.TRIM_HORIZON)
inputSchemaRequest.setInputStartingPositionConfiguration(configuration)
DiscoverInputSchemaResult inputSchemaResult = analyticsClient.discoverInputSchema(inputSchemaRequest)
input.setInputSchema(inputSchemaResult.inputSchema)
//Here you can set multiple inputs
request.withInputs([input])
KinesisFirehoseOutput firehoseOutput = new KinesisFirehoseOutput()
DeliveryStreamDescription firehoseResult = describeDeliveryStream(DELIVERY_STREAM_NAME)
firehoseOutput.setResourceARN(firehoseResult.getDeliveryStreamARN())
firehoseOutput.setRoleARN(iamHelperService.createAnalyticsFirehoseIamRole())
//Here setting our Firehose we have created earlier
Output output = new Output()
output.setKinesisFirehoseOutput(firehoseOutput)
output.setName(DELIVERY_STREAM_NAME)
DestinationSchema destinationSchema = new DestinationSchema()
destinationSchema.setRecordFormatType(RecordFormatType.CSV)
output.setDestinationSchema(destinationSchema)
request.withOutputs([output])
analyticsClient.createApplication(request)
waitForApplicationToBecomeAvailable(name)[/code]
Now when everything is ready to be launched, your app can push data into the stream via API.
Important to remember here is all your steps have to have appropriate IAM roles in order to have level of security for this type of apps. IAM service we will cover in some other posts.
Later when our app is running, we could use CloudWatch to see the load and add shards on demand if load is increasing. All that helps us to build easy scalable and manageable infrastructure which allows us to process GBs/per second and help business to be lightness quick with its profitable decisions.
If you have any queries or would like our team quickly to implement Real Time Big Data Analytics into your project please contact for a free quote.